
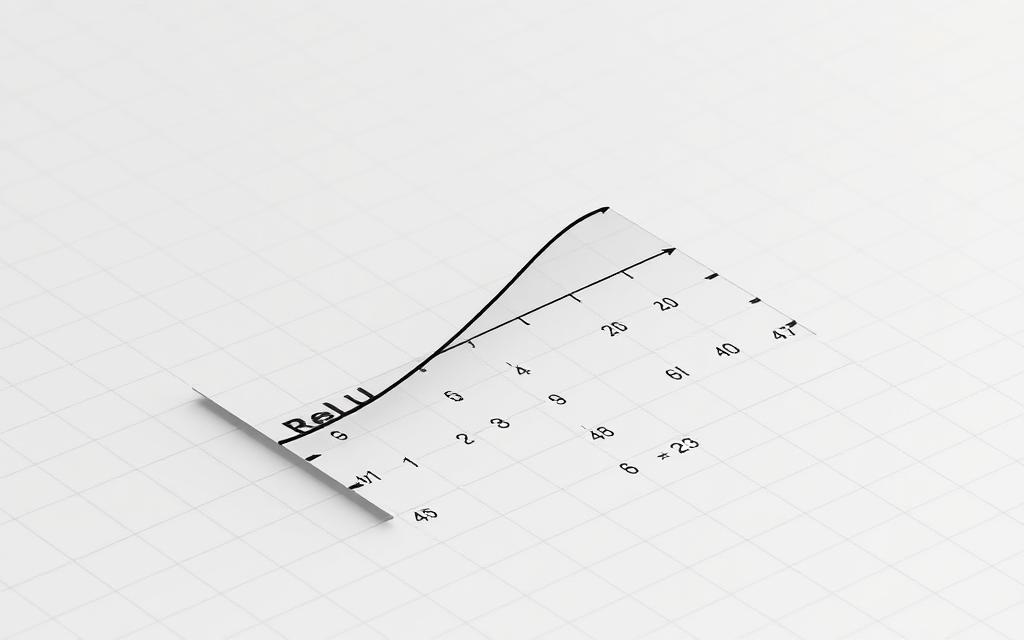
Contemporary deep learning architectures depend on a critical component that revolutionised neural network training. The rectified linear unit (ReLU) has emerged as this cornerstone, enabling breakthroughs across AI domains through its distinctive properties. Its adoption spans everything from image recognition systems to language models, reshaping modern machine learning frameworks.
The mathematical formula f(x) = max(0,x) belies its transformative impact. Unlike traditional activation functions, this approach introduces non-linearity while maintaining computational efficiency—a balance older methods like sigmoid rarely achieved. By outputting zero for negative inputs and linear positive values otherwise, it preserves gradient information essential for training.
One pivotal advantage lies in mitigating the vanishing gradient problem. Earlier techniques struggled with diminishing signal strength in deeper layers, stifling network complexity. ReLU’s design allows unobstructed gradient flow for positive inputs, accelerating convergence in multi-layered architectures.
That concept is easier to apply once you relate it to artificial neural network from scratch in a model-building workflow.
These characteristics have made it indispensable for cutting-edge applications. From powering convolutional networks in medical imaging to enabling transformer models in language processing, its influence permeates AI innovation. As researchers push neural networks to unprecedented depths, ReLU’s simplicity and efficacy keep it at the forefront of modern implementations.
Understanding What is ReLU function in deep learning?
Efficient data transformation is pivotal in artificial intelligence systems. The rectified linear unit operates through a straightforward rule: f(x) = max(0,x). This mechanism replaces negative values with zero while leaving positive numbers unchanged, acting as a digital gatekeeper for neural computations.
Definition and Basic Concept
Consider a matrix input like [[0, 3], [-2, 7]]. The rectified linear unit processes it as follows:
| Original Values | Post-Activation |
|---|---|
| 0 | 0 |
| 3 | 3 |
| -2 | 0 |
| 7 | 7 |
This thresholding mirrors biological systems where nerve cells only fire after reaching specific stimulation levels. Such sparse activation patterns reduce unnecessary calculations in multi-layered networks.
Role in Neuron Activation
Individual artificial neurons utilise this mechanism to decide their participation in processing signals. Approximately 50% of neurons typically remain inactive during forward propagation, creating efficient pathways for feature detection. This selective activation enables networks to prioritise relevant patterns while suppressing noise.
Modern implementations benefit from two key advantages:
- Zero computational cost for negative inputs
- Constant gradient flow for active neurons
These properties make the approach particularly effective in deep architectures where resource optimisation directly impacts training speed and model performance.
The Fundamentals of ReLU and Its Mathematical Properties
Neural computations rely on mathematical frameworks that balance simplicity with effectiveness. The rectified linear unit achieves this through a two-part rule: outputs mirror positive values and nullify others. This duality creates distinct computational behaviours critical for modern AI systems.

Function and Derivative
The core mechanism operates as R(z) = z when z > 0, otherwise zero. Its derivative follows suit: R’(z) = 1 for positive inputs, dropping to zero below the threshold. This creates a binary gradient mask during backpropagation:
- Active neurons propagate full error signals
- Inactive units block gradient flow entirely
Consider matrix X = [[0,3],[-2,7]]. The derivative mask becomes [[0,1],[0,1]], demonstrating how only positive elements influence weight updates. Some frameworks assign values between 0-1 at zero inputs, though most implementations treat them as inactive.
Handling of Negative Inputs
By zeroing sub-threshold values, the approach induces sparsity in network activations. Approximately half the neurons typically remain dormant during processing phases. This selective participation yields three key benefits:
- Reduced computational overhead
- Implicit regularisation against overfitting
- Linear growth in positive regions for stable training
The strategy avoids complex transformations applied to negative numbers, prioritising speed over nuanced handling. While this occasionally causes inactive neurons (the “dying ReLU” issue), most architectures mitigate this through proper initialisation techniques.
Comparing ReLU with Other Activation Functions
Modern neural architectures evolved through successive improvements in how artificial neurons process information. Traditional approaches like sigmoid and tanh once dominated neural computations, but inherent limitations prompted engineers to develop more efficient alternatives.
Sigmoid and Tanh Differences
The sigmoid mechanism S(z) = 1/(1 + e⁻ᶻ) compresses outputs between 0-1, creating saturation zones where gradients vanish. Though useful for probability estimations, this property hinders deep network training through diminished error signals.
Tanh’s (eᶻ – e⁻ᶻ)/(eᶻ + e⁻ᶻ) formula outputs values from -1-1, solving sigmoid’s asymmetry issue. However, both approaches share critical weaknesses:
- Exponential computations slow processing
- Persistent gradient decay in multi-layered systems
- Output saturation beyond certain thresholds
Variants Including Leaky ReLU and ELU
Engineers developed modified versions to address dormant neuron issues in standard implementations. Leaky variants introduce a slight slope (α=0.01) for negative inputs using R(z) = max(αz, z), preserving minimal gradient flow.
The Exponential Linear Unit (ELU) applies α(eᶻ -1) for sub-zero values, creating smooth transitions. Key advantages include:
- Reduced dead neuron occurrences
- Negative value handling without abrupt cutoffs
- Improved convergence in deeper architectures
These adaptations demonstrate how contemporary solutions balance computational efficiency with biological plausibility. While newer variants offer theoretical benefits, standard implementations remain favoured for most practical applications due to their simplicity and proven effectiveness.
Advantages of Using ReLU in Neural Networks
Breaking through computational barriers requires innovative approaches to neuron activation. The rectified linear unit’s design directly addresses two fundamental challenges in modern AI systems: maintaining signal strength and optimising resource usage.

Avoiding the Vanishing Gradient Problem
Traditional activation functions caused signal degradation in multi-layered architectures. When gradients become too small during backpropagation, weight updates stall. ReLU’s binary gradient structure (0 for negatives, 1 for positives) prevents multiplicative decay across layers.
This characteristic proves crucial for deep architectures. Over 80% of modern networks with 10+ layers utilise this approach. Unlike sigmoid’s curved saturation zones, the linear positive segment maintains consistent error signal strength.
Computational Efficiency and Simplicity
The max(0,x) operation requires minimal processing power compared to exponential calculations. This efficiency becomes critical when handling:
- High-dimensional image data
- Real-time inference tasks
- Large language models
Implementation advantages extend beyond raw speed. The absence of complex mathematical operations reduces coding errors and simplifies debugging. These factors collectively enable faster experimentation cycles and more scalable AI solutions.
Exploring the Role of Activation Functions in Deep Learning Models
Neural architectures derive their power from a crucial duality of operations. Linear computations handle feature combinations through matrix algebra, while nonlinear activations inject complexity into the system. This partnership allows models to evolve from simple pattern detectors to sophisticated reasoning engines.
Importance in Network Training
Activation mechanisms determine how neural networks process information during training phases. They transform weighted sums into usable signals for subsequent layers. Key contributions include:
- Enabling error backpropagation through differentiable operations
- Preventing signal saturation in multi-layered designs
- Introducing sparse activations for efficient resource use
“Without nonlinear activations, even the deepest networks would collapse into single-layer perceptrons,” notes Dr. Eleanor Hughes, AI researcher at Cambridge.
Impact on Model Learning Capability
Choice of activation function directly influences what patterns a system can recognise. Compare these operational characteristics:
| Operation Type | Purpose | Example | Impact |
|---|---|---|---|
| Linear | Feature combination | Matrix multiplication | Builds input relationships |
| Nonlinear | Complex mapping | Activation functions | Enables hierarchical learning |
Deeper layers leverage these nonlinear transformations to construct abstract concepts. Early layers might detect edges in images, while subsequent ones assemble these into shapes or objects. This hierarchical processing underpins modern architectures tackling tasks from medical diagnosis to autonomous navigation.
Performance metrics reveal stark contrasts between activation strategies. Models using appropriate nonlinearities achieve up to 40% faster convergence than those relying solely on linear operations. Proper selection remains paramount for balancing computational efficiency with learning potential in contemporary implementations.
Real-World Applications and Implementations of ReLU
Practical implementations reveal the true power of activation mechanisms across industries. Computer vision systems demonstrate particular effectiveness, with convolutional architectures achieving record-breaking performance in pattern recognition tasks.

Usage in Convolutional Architectures
Modern vision systems strategically position activation layers between convolution and pooling operations. This arrangement preserves spatial hierarchies while introducing essential nonlinear transformations. Popular frameworks like AlexNet and ResNet leverage this configuration for efficient feature extraction.
Key implementation advantages include:
- Zero computational overhead for negative feature maps
- Linear gradient propagation through active filters
- Automatic sparsity induction in deeper layers
Case Studies in Visual Recognition
The MNIST benchmark illustrates practical effectiveness. A standard convolutional model achieved 99.13% accuracy using conventional activation. When tested with experimental variants, performance dipped to 98.8% but recovered completely after just two fine-tuning epochs.
This resilience proves invaluable for production systems requiring:
- Stable inference pipelines
- Hardware optimisation potential
- Consistent memory usage patterns
Beyond imagery, transformer models utilise similar principles for language processing. Speech recognition systems and reinforcement learning frameworks also benefit from predictable activation behaviour, confirming the mechanism’s cross-domain versatility.
Benefits and Limitations of ReLU
Modern neural architectures balance performance trade-offs through strategic activation choices. While ReLU’s computational simplicity drives its popularity, practitioners must address inherent constraints when designing systems.

Advantages in Reducing Computational Demands
The activation’s threshold-based operation requires minimal processing power. Unlike exponential functions, it eliminates complex calculations for negative values, cutting memory usage by up to 30% in large models. This efficiency proves critical for mobile applications where resources are constrained.
Three key benefits emerge:
- Instantaneous forward/backward passes
- Simplified hardware implementation
- Reduced energy consumption during inference
These characteristics make it ideal for real-time systems handling video analysis or computational demands in edge devices.
Challenges such as Dying Neurons
The dying ReLU problem occurs when neurons persistently output zero. Once weights adjust to produce negative inputs, gradients vanish completely – halting learning. Research shows up to 15% of units can become inactive in poorly initialised networks.
Practical solutions include:
- He initialisation for weight matrices
- Leaky variants with small negative slopes
- Learning rate reduction strategies
Unbounded positive outputs present additional challenges. Without normalisation layers, activation magnitudes can destabilise training. Careful architecture design remains essential to harness ReLU’s strengths while mitigating risks.
Alternative Activation Functions in Modern Deep Learning
Modern AI systems demand adaptive solutions beyond conventional approaches. While ReLU dominates activation strategies, newer alternatives address specific architectural challenges. Engineers now balance computational efficiency with nuanced gradient management across diverse neural architectures.
Leaky ReLU and ELU exemplify evolutionary improvements. The former introduces minimal slopes for negative values, preventing neuron dormancy. ELU’s smooth negative curve enhances convergence in complex models. Both maintain linear positive responses while refining gradient flow.
Emerging variants like Swish and GELU demonstrate innovative thinking. These combine sigmoid-like gating with linear components, achieving better performance in transformer-based systems. However, increased computational complexity limits their adoption in resource-constrained environments.
Practical implementations reveal a clear trade-off hierarchy. Simpler functions excel in convolutional networks and edge devices. Advanced options prove valuable for language models requiring precise gradient control. This diversity enables tailored solutions without abandoning ReLU’s core principles.
The activation landscape continues evolving alongside hardware advancements. Future developments may prioritise energy efficiency or biological plausibility. Yet for most applications, ReLU’s blend of simplicity and effectiveness remains unmatched.
FAQ
How does the rectified linear unit differ from sigmoid or tanh in neural networks?
Unlike sigmoid or tanh, which squash inputs into a fixed range (e.g., 0–1 or -1–1), ReLU outputs the input directly for positive values and zero otherwise. This linearity for positive inputs preserves gradients, accelerating training while avoiding saturation issues common in sigmoid-based models.
Why is ReLU preferred for addressing the vanishing gradient problem?
Traditional activation functions like tanh or sigmoid suffer from small derivatives for extreme inputs, causing gradients to diminish during backpropagation. ReLU’s derivative is either 0 or 1, enabling stronger gradient flow and mitigating this issue in deeper architectures.
What challenges arise from ReLU’s handling of negative inputs?
ReLU sets all negative values to zero, which can lead to “dying neurons” – units that remain inactive and stop contributing to learning. Variants like Leaky ReLU or ELU address this by allowing small, non-zero outputs for negatives, maintaining gradient diversity.
How does ReLU enhance computational efficiency in training models?
The function involves simple thresholding operations, requiring minimal computation compared to exponential calculations in sigmoid or tanh. This efficiency is critical for large-scale networks, reducing training time and resource demands.
In what scenarios is ReLU commonly applied within deep learning frameworks?
ReLU dominates convolutional neural networks (CNNs) for tasks like image classification, where its non-linearity and efficiency help detect hierarchical features. Case studies in models like ResNet demonstrate its effectiveness in improving accuracy and convergence speed.
What alternatives exist to ReLU in modern architectures?
Variants such as Leaky ReLU, Parametric ReLU, and Exponential Linear Unit (ELU) offer solutions to ReLU’s limitations. These alternatives adjust how negative values are processed, balancing activation sparsity and gradient stability for specific use cases.
How does ReLU influence a model’s learning capability?
By introducing non-linearity without compressing outputs, ReLU enables networks to learn complex patterns. Its sparse activation – where only a subset of neurons fire – also promotes efficient feature representation, enhancing generalisation in tasks like speech recognition.
Why might deeper networks benefit more from ReLU than shallow ones?
Deeper architectures face amplified risks of vanishing gradients. ReLU’s gradient preservation across layers supports stable weight updates during backpropagation, making it indispensable for training multi-layered models like those in natural language processing.

 By
By






")